
Sometimes, infrastructure architecture matters – it can mask bottlenecks inherent in the application architecture. A large telecommunications customer, looking to modernize their infrastructure, spent well over $1M deploying new HCI for an old application. The application in question, built using a combination of off-the-shelf software and a customized back end using MySQL, was used as the primary call center support tracking system. Call center staff would use the application to track customers calling into support for their network or internet service – their call history, logging of the actions taken during the call, etc. As a core component of the customer support experience, this application is critical.
To ensure 100% consistency and integrity of transactions, and to ensure that not a single customer interaction is lost, the MySQL back end was deployed as a pair of independent database servers. When a call center employee answered a call and began either looking up customer history or recording a new call session, the connection to the database was distributed through a load-balancing layer to one of the two database servers. Every single write on either database was logged – synchronously – to the other database to copy all transactions to two locations. The customer had configured their log replication to sync_relay_log=1 to enable synchronization of the binary log to disk before transactions are committed. The MySql documentation explicitly calls this configuration out as the safest – yet also the slowest – due to the high number of writes required. *
The entire application was already virtualized, running on vSphere 5.0, on 5 year old servers, and a 7 year old EMC VMAX fibre-channel array. Furthermore, each MySQL server was built with only a single VMDK, and a single virtual SCSI adapter, making the synchronized write an extremely expensive operation in terms of performance because such a flush-write-acknowledge-release pattern is a single-threaded, blocking behavior – meaning no other storage operations can complete until that transaction is finished, unless there are additional storage devices to engage – which in this case there were not. Despite the age of the infrastructure – and the chosen deployment architecture – the application ran extraordinarily well.
Once the application was moved over to the new vSAN cluster, however, transactions per second dropped precipitously, effectively making the application useless for the call center. The customer ran multiple tests on all parts of the application – the web interface, the application tier containing the business / lookup logic for retrieving customer records, the load balancers, and of course the database. As it turns out, the database was simply unable to keep up with the number of users calling in, crashed repeatedly, and of course both the company and their customers were extremely frustrated. The application was migrated back to the legacy environment, and the call center proceeded to operate as normal.
What was the difference? Why did the application perform so poorly, despite having been migrated to new servers, new networking, and new, solid-state storage devices in the vSphere cluster?
The answer of course lies in the infrastructure itself. Most HCI solutions – including VMware vSAN – rely on persistent, solid state storage for the caching layer. This ensures that in the event of a power failure, transactions written to disk are not lost. Many array-based solutions, however, rely on a battery-backed memory architecture for caching purposes – including EMC VMAX. This effectively accomplishes the same thing – ensuring that transactions written to cache, but not yet destaged to permanent capacity, are not at risk of loss due to a power outage. DRAM, however, is able to achieve lookups (“references”) in nanoseconds, while solid state drives are able to perform lookups in milliseconds. Some quick math will reveal that despite all our advances in storage technology over the past 20 years, DRAM is still approximately one million times quicker than non-volatile, solid-state storage. There are of course other factors to consider, including network latency for protection of objects in a hyperconverged solution versus the latency of the fibre-channel network on the SAN for the VMAX. However, after additional testing and troubleshooting with both Dell and VMware support, it was determined the primary factor contributing to the loss of performance was the storage caching layer – the battery-backed cache on the VMAX was able to keep up with the necessary write transactions, whereas the caching layer on VSAN was not.
We were able to prove that similar performance was possible on the vSAN architecture, however, by taking a number of actions and changing the configuration of the virtual machine – none of which required changing any of the queries in the database.
- Increase threads and log writers for MySQL
- Increase the queue depth of the virtual SCSI controllers
- Increase the number of VMDKs and virtual SCSI adapters in the system.
- Increase MySQL threads to match new storage queue depths
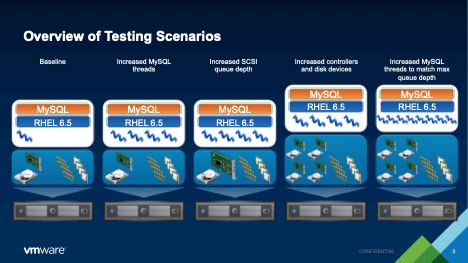
The largest gains were found after simply increasing the number of storage devices available to the system. We reconfigure the virtual machine with multiple VMDK files, multiple virtual SCSI adapters, and we created a logical volume across the (now four) VMDK files. This allowed us to essentially spread the storage load across multiple queues, which simultaneously gave MySQL more threads to use for storage writes as well. Latency and CPU time dropped, and the number of transactions per second increased to production levels.
The important takeaway is despite the initial poor performance after the initial migration to vSAN, simple changes to the virtual machine were able to remove the storage bottleneck. The customer was not aware of this potential bottleneck, as the previous array-based solution was able to keep up with the demands of the high-throughput, single-threaded write behavior.
* https://dev.mysql.com/doc/refman/5.6/en/replication-options-replica.html#sysvar_sync_relay_log: If the value of this variable is greater than 0, the MySQL server synchronizes its binary log to disk (using fdatasync()) after sync_binlog commit groups are written to the binary log. The default value of sync_binlog is 0, which does no synchronizing to diskóin this case, the server relies on the operating system to flush the binary log’s contents from time to time as for any other file. A value of 1 is the safest choice because in the event of a crash you lose at most one commit group from the binary log. However, it is also the slowest choice (unless the disk has a battery-backed cache, which makes synchronization very fast).
